from forensicface.app import ForensicFace
import forensicface
forensicface.__version__'0.7.1'from forensicface.app import ForensicFace
import forensicface
forensicface.__version__'0.7.1'ff = ForensicFace(
use_gpu=True,
extended=True,
det_thresh=0.5,
models=["sepaelv2", "sepaelv6"],
concat_embeddings=False,
)2026-05-23 23:31:18.399858704 [W:onnxruntime:, session_state.cc:1359 VerifyEachNodeIsAssignedToAnEp] Some nodes were not assigned to the preferred execution providers which may or may not have an negative impact on performance. e.g. ORT explicitly assigns shape related ops to CPU to improve perf. 2026-05-23 23:31:18.400023681 [W:onnxruntime:, session_state.cc:1361 VerifyEachNodeIsAssignedToAnEp] Rerunning with verbose output on a non-minimal build will show node assignments.
[ForensicFace] Initialized with configuration:
loaded_models=['sepaelv2', 'sepaelv6']
modules=['detection', 'headpose', 'genderage', 'cr_fiqa']
det_size=(320, 320)
session_providers=all models use CUDAExecutionProvider
ff.rec_inference_sessions[<onnxruntime.capi.onnxruntime_inference_collection.InferenceSession at 0x73eb341c3230>,
<onnxruntime.capi.onnxruntime_inference_collection.InferenceSession at 0x73eb34085590>]ret = ff.process_image("obama.png")
ret.keys()FutureWarning: process_image: The return of this function when 'single_face = True' will change in a future release.
Instead of returning a dict, it will return a list (with one dict). dict_keys(['ipd', 'fiqa_score', 'gender', 'age', 'yaw', 'pitch', 'roll', 'det_score', 'keypoints', 'bbox', 'embedding_sepaelv2', 'embedding_sepaelv6', 'aligned_face'])ret = ff.process_image("tela.png", single_face=False)
len(ret), ret[0].keys(), ret[1].keys()(8,
dict_keys(['ipd', 'fiqa_score', 'gender', 'age', 'yaw', 'pitch', 'roll', 'det_score', 'keypoints', 'bbox', 'embedding_sepaelv2', 'embedding_sepaelv6', 'aligned_face']),
dict_keys(['ipd', 'fiqa_score', 'gender', 'age', 'yaw', 'pitch', 'roll', 'det_score', 'keypoints', 'bbox', 'embedding_sepaelv2', 'embedding_sepaelv6', 'aligned_face']))ret = ff.process_image_single_face("obama.png")
ret.keys()FutureWarning: process_image: The return of this function when 'single_face = True' will change in a future release.
Instead of returning a dict, it will return a list (with one dict). dict_keys(['ipd', 'fiqa_score', 'gender', 'age', 'yaw', 'pitch', 'roll', 'det_score', 'keypoints', 'bbox', 'embedding_sepaelv2', 'embedding_sepaelv6', 'aligned_face'])ret["embedding_sepaelv2"].shape, ret["embedding_sepaelv6"].shape((512,), (512,))# output Python interpreter and packages information
# useful for reproducing results
ff.environment{'Python version': '3.13.13 (main, Apr 14 2026, 14:28:56) [Clang 22.1.3 ]',
'annotated-types': '0.7.0',
'anyio': '4.13.0',
'argon2-cffi': '25.1.0',
'argon2-cffi-bindings': '25.1.0',
'arrow': '1.4.0',
'asttokens': '3.0.1',
'async-lru': '2.3.0',
'attrs': '26.1.0',
'babel': '2.18.0',
'beartype': '0.22.9',
'beautifulsoup4': '4.14.3',
'black': '26.3.1',
'bleach': '6.3.0',
'certifi': '2026.4.22',
'cffi': '2.0.0',
'charset-normalizer': '3.4.7',
'click': '8.3.3',
'colorama': '0.4.6',
'comm': '0.2.3',
'contourpy': '1.3.3',
'cycler': '0.12.1',
'debugpy': '1.8.20',
'decorator': '5.2.1',
'defusedxml': '0.7.1',
'executing': '2.2.1',
'fastjsonschema': '2.21.2',
'flatbuffers': '25.12.19',
'fonttools': '4.62.1',
'forensicface': '0.7.1',
'fqdn': '1.5.1',
'griffe': '2.0.2',
'griffecli': '2.0.2',
'griffelib': '2.0.2',
'h11': '0.16.0',
'httpcore': '1.0.9',
'httpx': '0.28.1',
'idna': '3.13',
'ImageIO': '2.37.3',
'importlib_metadata': '9.0.0',
'importlib_resources': '7.1.0',
'imutils': '0.5.4',
'iniconfig': '2.3.0',
'ipykernel': '7.2.0',
'ipython': '9.13.0',
'ipython_pygments_lexers': '1.1.1',
'ipywidgets': '8.1.8',
'isoduration': '20.11.0',
'jedi': '0.20.0',
'Jinja2': '3.1.6',
'json5': '0.14.0',
'jsonpointer': '3.1.1',
'jsonschema': '4.26.0',
'jsonschema-specifications': '2025.9.1',
'jupyter': '1.1.1',
'jupyter-console': '6.6.3',
'jupyter-events': '0.12.1',
'jupyter-lsp': '2.3.1',
'jupyter_client': '8.8.0',
'jupyter_core': '5.9.1',
'jupyter_server': '2.17.0',
'jupyter_server_terminals': '0.5.4',
'jupyterlab': '4.5.7',
'jupyterlab_pygments': '0.3.0',
'jupyterlab_server': '2.28.0',
'jupyterlab_widgets': '3.0.16',
'kiwisolver': '1.5.0',
'lark': '1.3.1',
'lazy-loader': '0.5',
'markdown-it-py': '4.0.0',
'MarkupSafe': '3.0.3',
'matplotlib': '3.10.9',
'matplotlib-inline': '0.2.1',
'mdurl': '0.1.2',
'mistune': '3.2.0',
'ml_dtypes': '0.5.4',
'mypy_extensions': '1.1.0',
'nbclient': '0.10.4',
'nbconvert': '7.17.1',
'nbformat': '5.10.4',
'nest-asyncio': '1.6.0',
'networkx': '3.6.1',
'notebook': '7.5.6',
'notebook_shim': '0.2.4',
'numpy': '2.4.4',
'nvidia-cublas-cu12': '12.9.2.10',
'nvidia-cuda-nvrtc-cu12': '12.9.86',
'nvidia-cuda-runtime-cu12': '12.9.79',
'nvidia-cudnn-cu12': '9.21.1.3',
'nvidia-cufft-cu12': '11.4.1.4',
'nvidia-curand-cu12': '10.3.10.19',
'nvidia-nvjitlink-cu12': '12.9.86',
'onnx': '1.21.0',
'onnxruntime-gpu': '1.25.0',
'opencv-python-headless': '4.13.0.92',
'packaging': '26.2',
'pandas': '3.0.2',
'pandocfilters': '1.5.1',
'parso': '0.8.7',
'pathspec': '1.1.1',
'pexpect': '4.9.0',
'pillow': '12.2.0',
'platformdirs': '4.9.6',
'pluggy': '1.6.0',
'plum-dispatch': '2.9.0',
'prometheus_client': '0.25.0',
'prompt_toolkit': '3.0.52',
'protobuf': '7.34.1',
'psutil': '7.2.2',
'ptyprocess': '0.7.0',
'pure_eval': '0.2.3',
'pycparser': '3.0',
'pydantic': '2.13.3',
'pydantic_core': '2.46.3',
'Pygments': '2.20.0',
'pyparsing': '3.3.2',
'pytest': '9.0.3',
'python-dateutil': '2.9.0.post0',
'python-json-logger': '4.1.0',
'pytokens': '0.4.1',
'PyYAML': '6.0.3',
'pyzmq': '27.1.0',
'quartodoc': '0.11.1',
'referencing': '0.37.0',
'requests': '2.33.1',
'rfc3339-validator': '0.1.4',
'rfc3986-validator': '0.1.1',
'rfc3987-syntax': '1.1.0',
'rich': '15.0.0',
'rpds-py': '0.30.0',
'scikit-image': '0.26.0',
'scipy': '1.17.1',
'Send2Trash': '2.1.0',
'setuptools': '82.0.1',
'six': '1.17.0',
'soupsieve': '2.8.3',
'sphobjinv': '2.4',
'stack-data': '0.6.3',
'tabulate': '0.10.0',
'terminado': '0.18.1',
'tifffile': '2026.4.11',
'tinycss2': '1.4.0',
'tornado': '6.5.5',
'tqdm': '4.67.3',
'traitlets': '5.14.3',
'typing-inspection': '0.4.2',
'typing_extensions': '4.15.0',
'tzdata': '2026.2',
'uri-template': '1.3.0',
'urllib3': '2.6.3',
'watchdog': '6.0.0',
'wcwidth': '0.7.0',
'webcolors': '25.10.0',
'webencodings': '0.5.1',
'websocket-client': '1.9.0',
'widgetsnbextension': '4.0.15',
'zipp': '3.23.1'}result = ff.process_image("obama2.png", single_face=True, draw_keypoints=True)
result.keys(), result["keypoints"], result["ipd"], result[
"embedding_sepaelv2"
].shape, result["embedding_sepaelv6"].shape, result["det_score"](dict_keys(['ipd', 'fiqa_score', 'gender', 'age', 'yaw', 'pitch', 'roll', 'det_score', 'keypoints', 'bbox', 'embedding_sepaelv2', 'embedding_sepaelv6', 'aligned_face']),
array([[ 61.43039 , 87.56812 ],
[103.14895 , 97.624146],
[ 61.40738 , 114.31132 ],
[ 50.040977, 143.41942 ],
[ 82.59716 , 152.3282 ]], dtype=float32),
np.float32(42.91342),
(512,),
(512,),
0.8312392234802246)import matplotlib.pyplot as plt
plt.imshow(result["aligned_face"])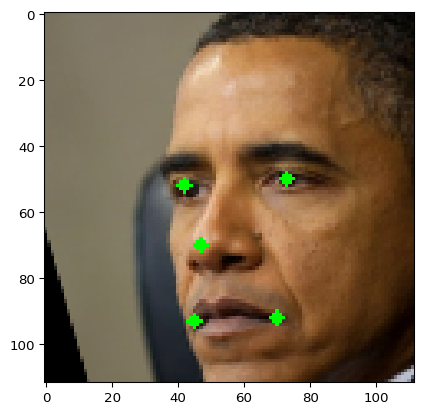
import cv2
imgs = [cv2.imread(x) for x in ["obama2.png", "obama.png"]]
mosaic = ff.build_mosaic(imgs, mosaic_shape=(2, 1))
plt.imshow(mosaic[:, :, ::-1])Warning: A list of arrays was passed as argument. Make sure image arrays are in BGR format.
ret = ff.process_images_batch(imgs, single_face=True, batch_size=16)
len(ret), ret[0].keys(), ret[0]["keypoints"].shape, ret[0]["ipd"], ret[0][
"embedding_sepaelv6"
].shape, ret[0]["det_score"](2,
dict_keys(['ipd', 'fiqa_score', 'gender', 'age', 'yaw', 'pitch', 'roll', 'det_score', 'keypoints', 'bbox', 'embedding_sepaelv2', 'embedding_sepaelv6', 'aligned_face']),
(5, 2),
np.float32(42.91342),
(512,),
0.8312392234802246)ret = [ff.detect_and_align(x) for x in imgs]
for i, r in enumerate(ret):
print(f"Image {i}:")
print(" Aligned keypoints shape:", r["aligned_keypoints"].shape)
print(" Aligned face shape:", r["aligned_face"].shape)Image 0:
Aligned keypoints shape: (5, 2)
Aligned face shape: (112, 112, 3)
Image 1:
Aligned keypoints shape: (5, 2)
Aligned face shape: (112, 112, 3)results = ff.process_image("tela.png", single_face=False, draw_keypoints=True)
results[0].keys(), results[0]["keypoints"], results[0]["bbox"], results[0]["det_score"](dict_keys(['ipd', 'fiqa_score', 'gender', 'age', 'yaw', 'pitch', 'roll', 'det_score', 'keypoints', 'bbox', 'embedding_sepaelv2', 'embedding_sepaelv6', 'aligned_face']),
array([[471.4288 , 418.60376],
[522.69116, 418.0571 ],
[498.821 , 449.0871 ],
[479.34802, 476.44247],
[514.3323 , 476.0735 ]], dtype=float32),
array([441, 355, 548, 506]),
0.8962146043777466)Calcula a similaridade cosseno entre as embeddings extraídas de cada imagem. Assume que cada imagem só possui uma face. Não compatível com concat_embeddings=False.
ff = ForensicFace(models=["sepaelv2", "sepaelv6"], concat_embeddings=True)2026-05-23 23:31:24.639351783 [W:onnxruntime:, session_state.cc:1359 VerifyEachNodeIsAssignedToAnEp] Some nodes were not assigned to the preferred execution providers which may or may not have an negative impact on performance. e.g. ORT explicitly assigns shape related ops to CPU to improve perf. 2026-05-23 23:31:24.639412190 [W:onnxruntime:, session_state.cc:1361 VerifyEachNodeIsAssignedToAnEp] Rerunning with verbose output on a non-minimal build will show node assignments.
[ForensicFace] Initialized with configuration:
loaded_models=['sepaelv2', 'sepaelv6']
modules=['detection', 'headpose', 'genderage', 'cr_fiqa']
det_size=(320, 320)
session_providers=all models use CUDAExecutionProvider
ff.compare("obama.png", "obama2.png")np.float32(0.8094356)Calcula a média das embeddings com ponderação por qualidade de cada imagem facial.
aggregated = ff.aggregate_from_images(["obama.png", "obama2.png"], quality_weight=True)
aggregated.shape(1024,)Detecta faces em quadros de vídeo e exporta cada face para um arquivo PNG. É possível exportar um arquivo jsonl com metadados das faces detectadas, incluindo as embeddings.
ff.extract_faces(
video_path="/home/rafael/video/video.mp4",
start_from=0,
every_n_frames=600,
dest_folder="/home/rafael/video_faces",
export_metadata=True,
)
Frames processed: 0/14 | Time elapsed: 00:00
Frames processed: 1/14 | Time elapsed: 00:00
Frames processed: 2/14 | Time elapsed: 00:00
Frames processed: 3/14 | Time elapsed: 00:01
Frames processed: 4/14 | Time elapsed: 00:01
Frames processed: 5/14 | Time elapsed: 00:01
Frames processed: 6/14 | Time elapsed: 00:02
Frames processed: 7/14 | Time elapsed: 00:02
Frames processed: 8/14 | Time elapsed: 00:03
Frames processed: 9/14 | Time elapsed: 00:03
Frames processed: 10/14 | Time elapsed: 00:03
Frames processed: 11/14 | Time elapsed: 00:04
Frames processed: 12/14 | Time elapsed: 00:04
Frames processed: 13/14 | Time elapsed: 00:05
Frames processed: 14/14 | Time elapsed: 00:05
Frames processed: 14/14 | Time elapsed: 00:0512ff = ForensicFace(extended=True, models=["sepaelv2", "sepaelv4"])[ForensicFace] Initialized with configuration:
loaded_models=['sepaelv2', 'sepaelv4']
modules=['detection', 'headpose', 'genderage', 'cr_fiqa']
det_size=(320, 320)
session_providers=all models use CUDAExecutionProvider
import numpy as np
ret = ff.process_image("obama.png", single_face=True)
ret2 = ff.process_aligned_face_image(ret["aligned_face"])
np.allclose(ret["embedding"], ret2["embedding"])FutureWarning: process_image: The return of this function when 'single_face = True' will change in a future release.
Instead of returning a dict, it will return a list (with one dict). Trueret2["embedding"].shape(1024,)ret["fiqa_score"], ret2["fiqa_score"](np.float32(2.1981096), np.float32(2.1981096))